Kafka share groups scale throughput beyond partition limits
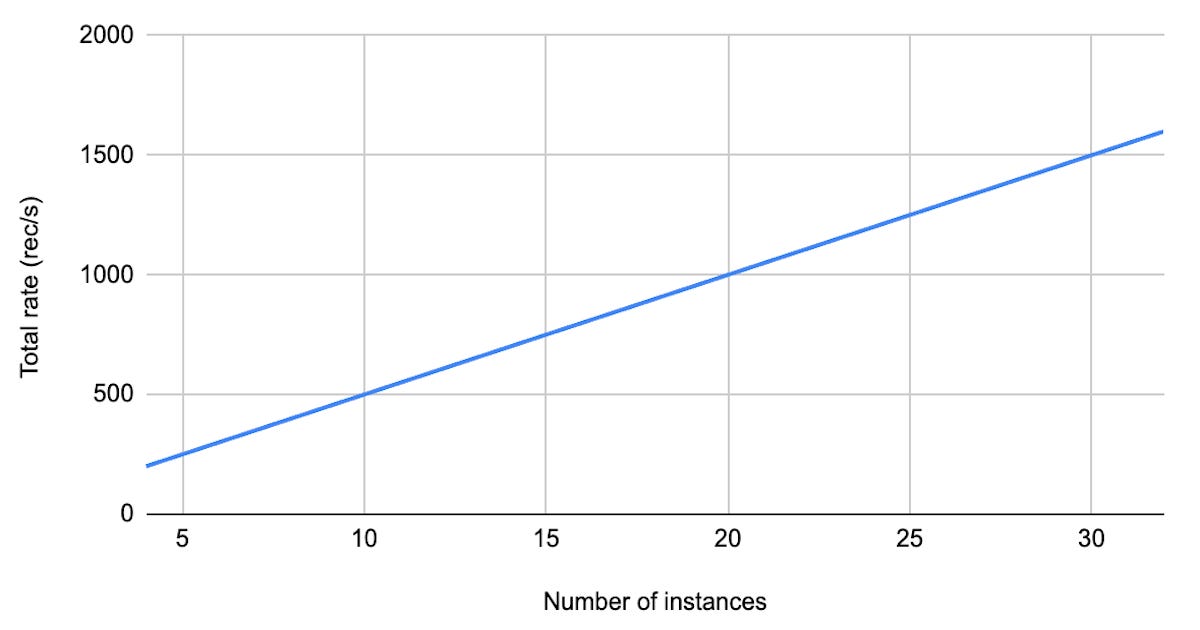
A technical analysis demonstrates that Apache Kafka's new Queues feature, specifically share groups, can significantly increase consumer throughput by mitigating head-of-line blocking when message processing involves delays, showing linear scaling up to at least an 8x increase. This scaling comes with the trade-off of losing ordering guarantees for messages. The benchmark results indicate that share groups can be used to scale processing beyond the number of partitions.
Key Takeaways
- The benchmark used the same setup as the prior post, but added configurable processing delays to model IO.
- At 200ms delay, each instance processed 5 records per second; at 20ms, 50 rec/s; at 5ms, about 196 rec/s; and at 1ms, about 925 rec/s.
- Standard and share-group consumers matched at 4 instances because the test topic had 4 partitions.
- Share groups were scaled to 8, 16, and 32 instances, and total processing rate increased linearly in each case.
- The main downside is that multiple instances can consume from the same partition, so message ordering is no longer guaranteed.
Why It Matters
For workloads with head-of-line blocking, Kafka’s share groups offer a way to push consumer throughput past the partition count. In these tests, delays from 1ms to 200ms made the benefit visible, with linear scaling out to 32 instances and at least an 8x throughput increase. That matters most for pipelines that wait on external IO, but the ordering trade-off is real: if message sequence matters, share groups may not be acceptable. The next signal to watch is where the scaling curve stops flattening as instance counts rise beyond 32.
Read full article at streamingdata.tech