NVIDIA’s VideoITG targets better frame selection for Video-LLMs
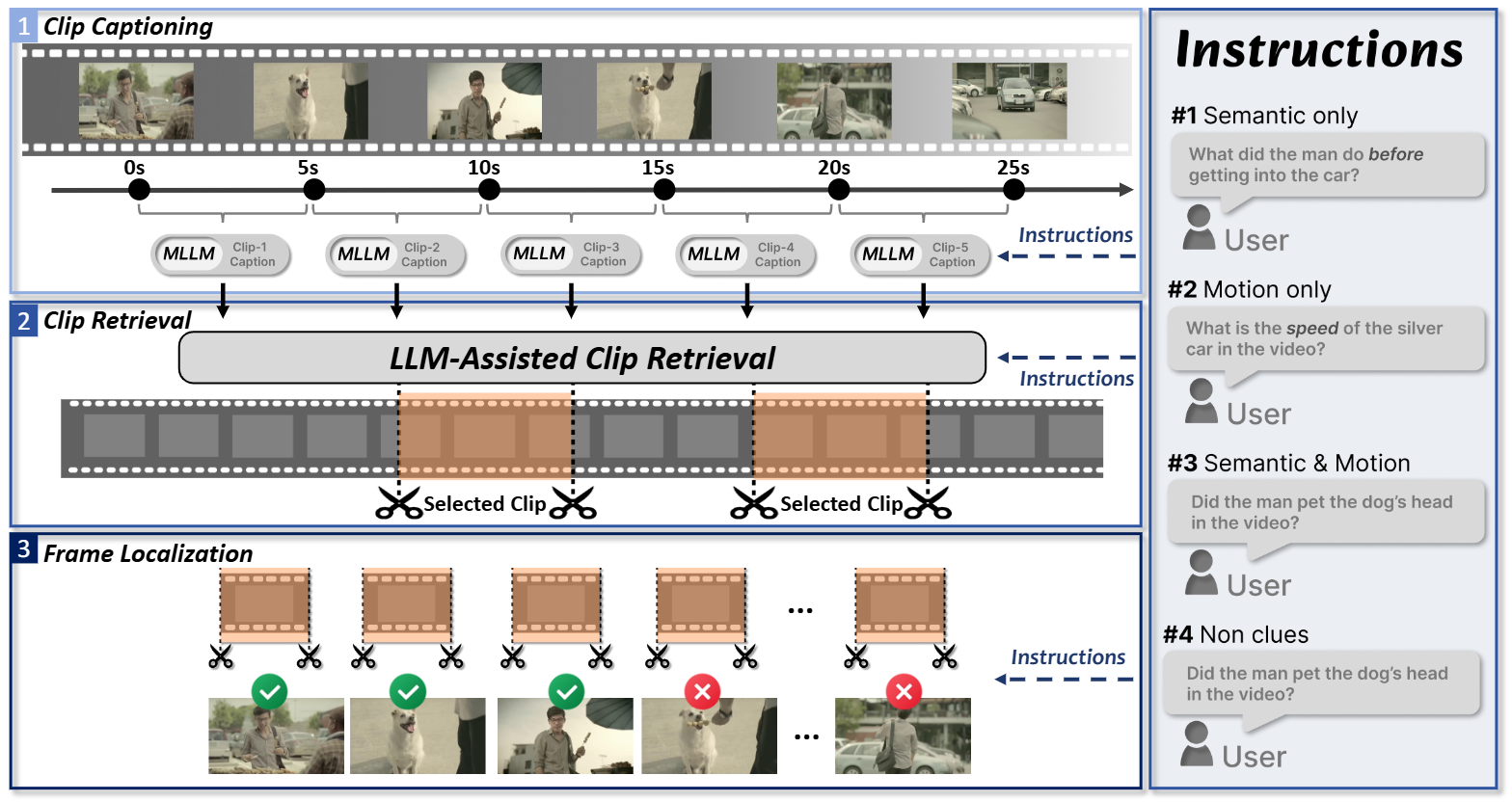
NVIDIA Research has introduced VideoITG, a new framework using "Instructed Temporal Grounding" to improve video understanding for Video Large Language Models (Video-LLMs). The framework includes the VidThinker pipeline for automated annotation, creating the VideoITG-40K dataset with 40K videos and 500K temporal grounding annotations to enhance frame sampling strategies based on user instructions.
Key Takeaways
- VideoITG is designed to adapt frame sampling to user instructions rather than rely only on redundancy reduction or unsupervised event localization.
- VidThinker automates annotation through instruction-conditioned captioning, relevant clip retrieval, and fine-grained frame localization.
- VideoITG-40K includes 40,000 videos and 500,000 temporal grounding annotations.
- NVIDIA says the plug-and-play VideoITG model uses Video-LLMs’ visual-language alignment and reasoning for discriminative frame selection.
- The company says VideoITG improves results on multiple multimodal video understanding benchmarks.
Why It Matters
VideoITG addresses a specific bottleneck for Video-LLMs: picking the most informative frames from long videos when instructions and temporal cues matter. The broader point is practical, not abstract — NVIDIA is packaging a dataset, annotation pipeline, and model design around that problem, with VidThinker doing the labeling work at scale. For teams building video understanding systems, the relevant signal is whether this approach holds up across more Video-LLMs and model sizes. NVIDIA already says it extends to multiple benchmarks, so the next thing to watch is how VideoITG performs on other long-video tasks and sampling setups.
Read full article at nvlabs.github.io