VisualClaw cutting video AI processing costs by up to 99%
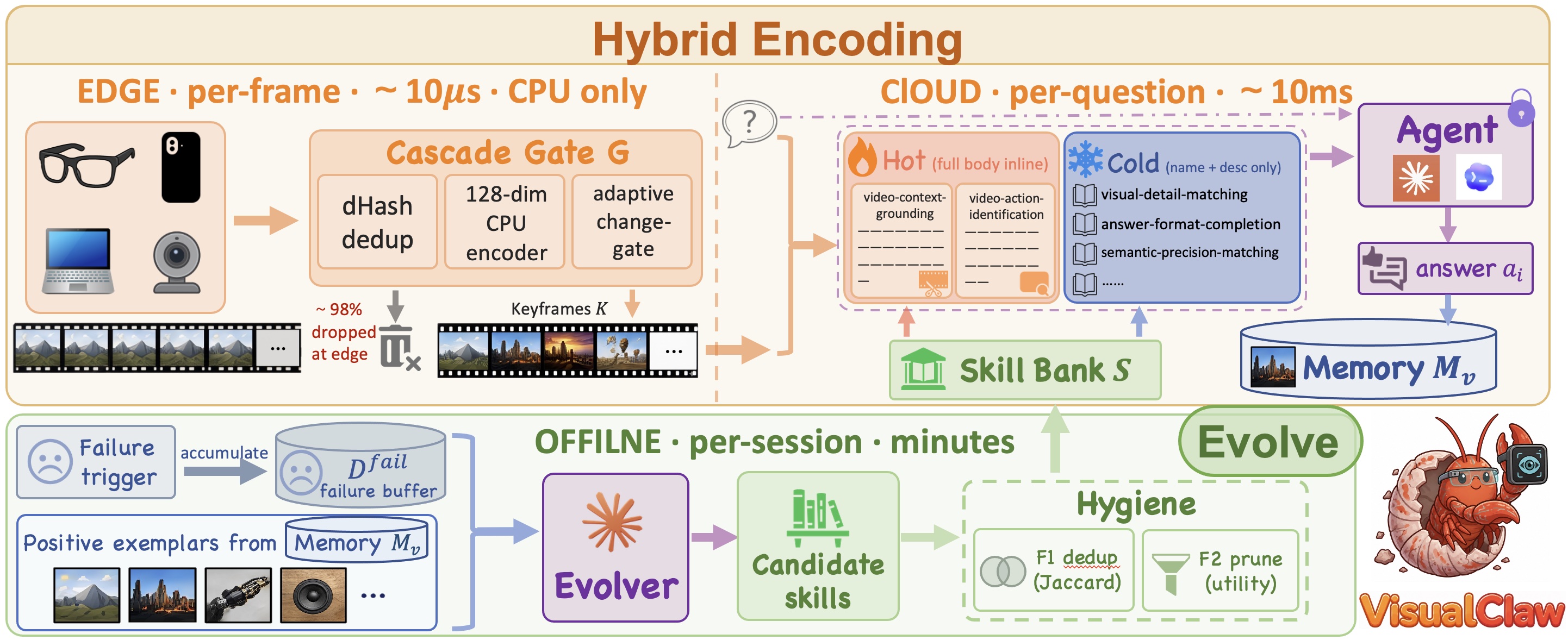
Researchers have introduced VisualClaw, a real-time personalized AI agent designed to filter visual evidence, reason with cloud VLMs, and evolve skills, significantly reducing video processing costs by up to 99.3%. It employs hybrid encoding and self-evolving skill banks to improve accuracy and cost efficiency in multimodal agentic workflows while addressing deployment gaps like expensive video frames and static model scaffolds. The system includes VisualClawArena, a benchmark for evaluating visual evidence use in executable multimodal workflows with 200 scenarios.
Key Takeaways
- Reduces Gemini 3 Flash API spend by 99.3% on Video-MME long benchmarks compared to full-frame uploads.
- Implements a cascaded encoding gate using 128-dimensional CPU encoders to filter redundant streaming frames at the edge.
- Introduces VisualClawArena, a 200-scenario benchmark for evaluating visual evidence in executable agentic workflows.
- Employs a three-timescale system that separates sub-second frame filtering from lower-frequency skill evolution.
- Maintains competitive accuracy, achieving a 68.4% score on EgoSchema with the evolved Gemini 3 Flash configuration.
Why It Matters
VisualClaw addresses the primary economic barrier to 24/7 visual AI assistants: the prohibitive cost of continuous cloud frame processing. By shifting filtering to the edge and using retrieved 'skills' instead of massive prompts, it enables personalized agents to operate sustainably over long deployment windows. For the streaming industry, this suggests a pivot toward leaner, metadata-driven architectures where cloud VLMs are triggered only by significant visual change. The release of VisualClawArena also provides a more rigorous standard for assessing how agents reconcile visual facts with files in real-world environments. Watch for the integration of these hybrid encoding gates into smart glass and security camera firmware within the next 12 months.
Additional Context
The launch of VisualClaw coincides with a broader shift in 2026 toward 'Agentic Video Workflows,' where video is treated as a queryable data source rather than a passive asset, per Aragon Research in June 2026. This trend is supported by the emergence of high-efficiency models like Gemini 3 Flash and GPT-5.2, which have redefined the speed-price floor for vision tasks. According to llm-stats.com in early 2026, Gemini 3 Flash has become a preferred production workhorse due to its 1-million-token context window and pricing that is roughly 4.3x cheaper than GPT-5.2 on a blended basis. This economic advantage is critical as enterprises manage 'agent sprawl' across multiple cloud and edge platforms. Simultaneously, the competitive landscape for multimodal agents is diversifying with the arrival of open-weight alternatives. In June 2026, developers introduced MiniMax M3, which combines a million-token context window with native computer-use capabilities, often outperforming proprietary APIs on coding benchmarks like SWE-Bench Pro, per devflokers reporting. To manage this complexity, firms are increasingly turning to 'AI agent control planes' to coordinate journey state and knowledge governance across different vendors, as noted by Opus Research in June 2026. These structural shifts suggest that while cost-reduction tools like VisualClaw are vital, the next industry bottleneck will be the governance and interoperability of the agents themselves as they move deeper into the physical world.
Read full article at ucsc-vlaa.github.io